Python List Growth Throwdown

Inplace List Addition vs. List Extend
I wanted to know whether it was “better” to do
some_list += another_listor
some_list.extend(another_list)So I cooked this up:
import timeit
results = {}
for i in xrange(100):
add_list = "[" + ", ".join(str(x) for x in xrange(i)) + "]"
inplace_add = timeit.timeit("l += " + add_list, setup="l = ['initial_item']", number=1000000)
extend = timeit.timeit("l.extend({})".format(add_list), setup="l = ['initial_item']", number=1000000)
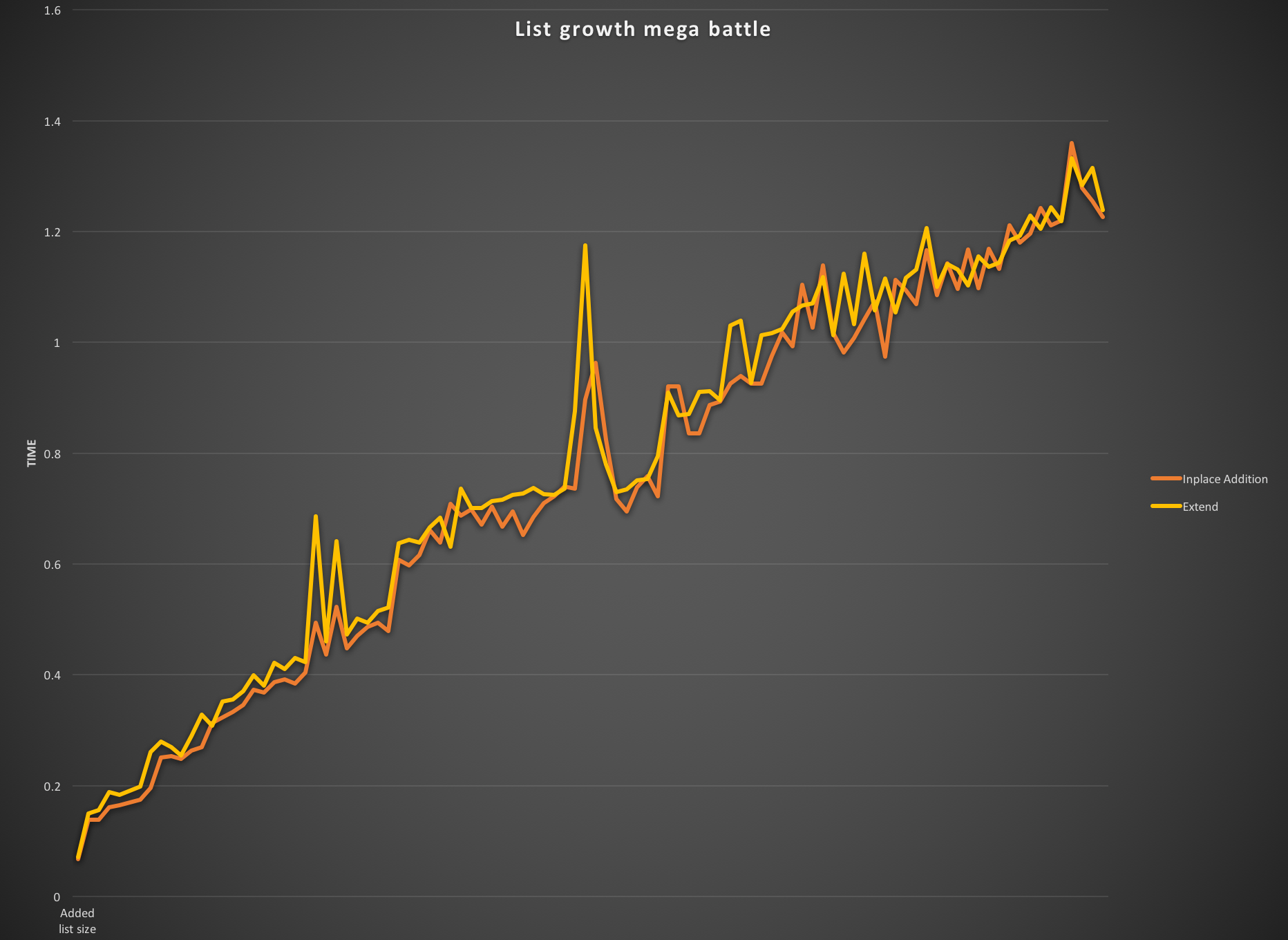
results[i] = (inplace_add, extend)Winner-ish
The in-place addition method (theoretically called when you use the ‘+=’ operator with lists as the left and right sides) is marginally faster. But not enough to make me really care whether to use one vs. the other.
Methodology
Just for safesies I tried this with a variety of right-hand list sizes, with 1-100 elements. I then timed each one 1,000,000 times. There are some strange bumps in the graph where the extend method beats in-place addition, but I attribute this to my computer having to work harder for the chorus of this sweet Mastodon song I’m listening to.
Further…
Apparently once the lists you’re trying to add together get longer (about 14 items in the rh-side), itertools.chain is much faster, for the initial extension…
import timeit
results = {}
for i in xrange(100):
add_list = "[" + ", ".join(str(x) for x in xrange(i)) + "]"
inplace_add = timeit.timeit("l += " + add_list, setup="l = ['initial_item']", number=1000000)
extend = timeit.timeit("l.extend({})".format(add_list), setup="l = ['initial_item']", number=1000000)
chain = timeit.timeit("x = itertools.chain(l, {})".format(add_list), setup="l = ['initial_item']", number=1000000)
results[i] = (inplace_add, extend, chain)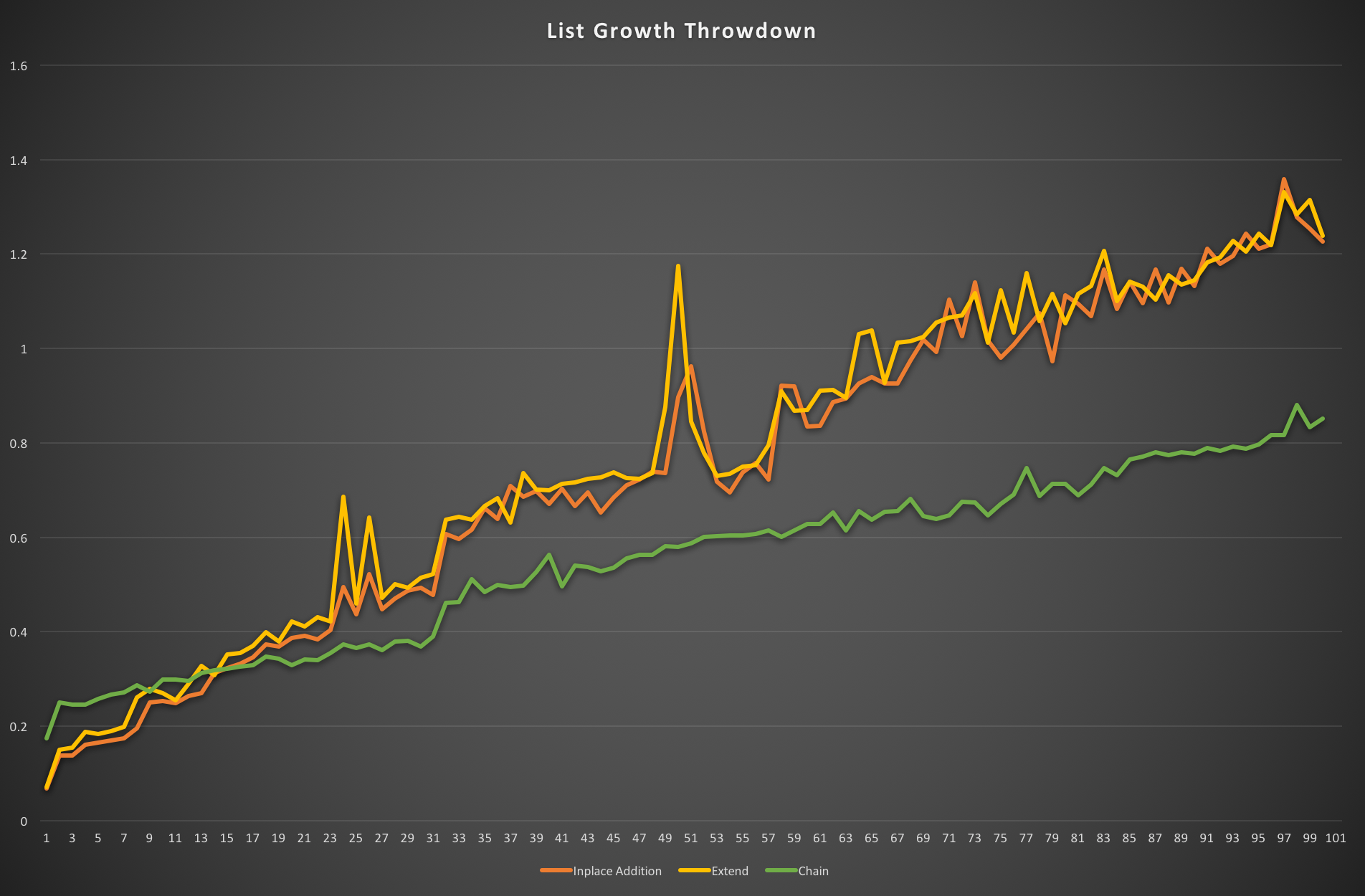 However, the overhead of chain for iteration means that it is slightly slower for iteration.
However, the overhead of chain for iteration means that it is slightly slower for iteration.
Round 2… Fight!
add_list = "[" + ", ".join(str(x) for x in xrange(100)) + "]"
chained = timeit.timeit("for _ in itertools.chain(l, {}):pass".format(add_list), setup="l = ['initial_item']", number=1000000)
grown = timeit.timeit("for _ in l + {}):pass".format(add_list), setup="l = ['initial_item']", number=1000000)
print "Chained: {} Grown: {}".format(chained, grown)
print "Chained: {:.4}s Grown: {:.4}s Ratio: {:.2%}%".format(chained, grown, grown / chained)
# Chained: 2.553s Grown: 2.272s Ratio: 88.98%%So it’s marginally faster to chain two iterables if one is over about 14 items, but then not as fast to actually iterate over them. My assumption is that (I’m not going to test it) that as you perform list += or extend more times, the overhead of chain dissolves into the extra cost of the list growth.
My recommendation? Don’t be such a nerd, and just use what you like the look of and are willing to maintain! Using += is simple, succinct, and performs better, and everyone who knows python will recognize what’s happening. Use extend if you want to be marginally more self-documenting. Use chain if you’re a greybeard who is into functional programming, or you’ve got a bunch of generators and don’t want to dump them into RAM by converting them to lists first.
But if speed actually matters for you, then profile it yourself! 